My Top 5 Papers of 2018
In no particular order, I’ll list my 5 favorite papers from 2018. For each one, I’ll include a quick summary and what mention what made it stand out to me. The papers are all from either computer vision or reinforcement learning—the topics I was interested in most in 2018.
1. Neural Scene Representation and Rendering
By S. M. Ali Eslami and many others at Google Deepmind, published in Science magazine [pre-print (warning! clicking the link auto-downloads a pdf)]
In this paper, they tackled the task of learning 3D representations of virtual scenes- representations that can be used to “imagine” (render) scenes from previsously unseen viewpoints. They accomplished this by introducing the Generative Query Network (GQN), a generative model comprised of a representation network and a generation network. They trained it by providing the representation network with multiple views of a scene as input and asking the generation network to render the scene from a new viewpoint. Here is a link to DeepMind’s blogpost on it.
I was really excited when I saw this paper (and so were a lot of other people) mainly becuase of the jaw-dropping visual results. GQN learns colors of objects and can demonstrate understanding of the numbers of objects in a scene. There are a lot of potential applications of GQN, especially when it inevitably gets scaled up to real-world indoor/outdoor scenes. Some uses for model-based RL and SLAM come to mind.
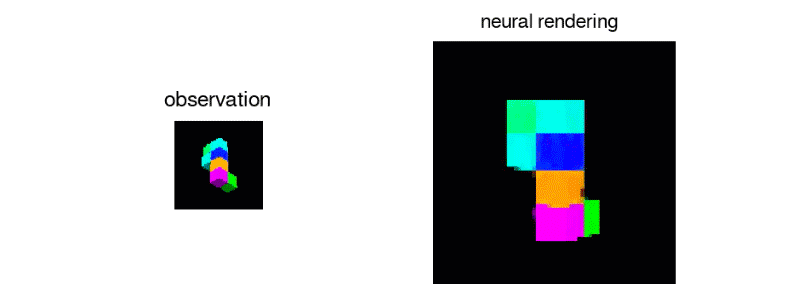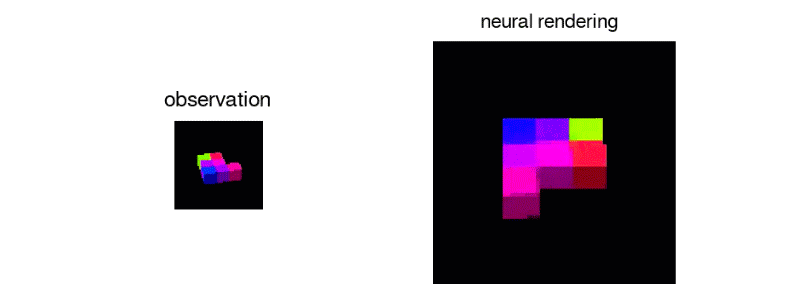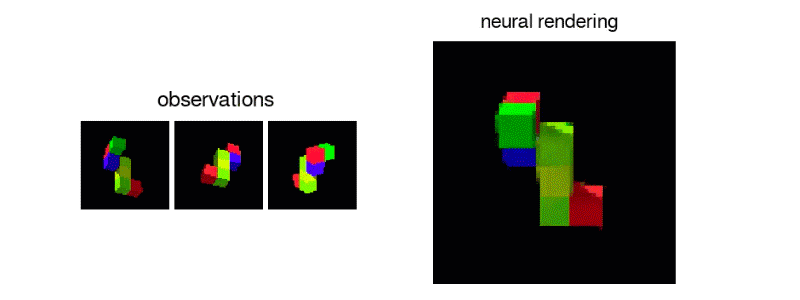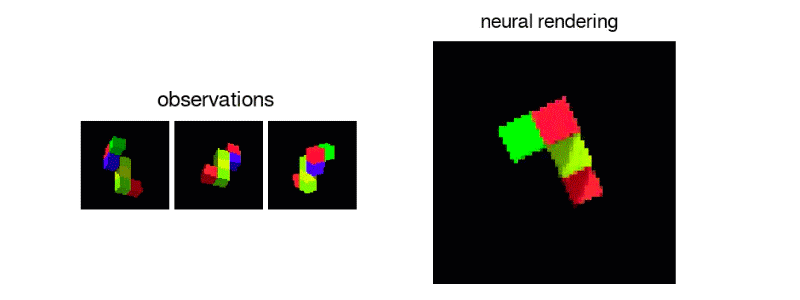
2. The 2 “Addressing X in Y” Deep RL papers
Addressing Function Approximation Error in Actor-Critic Methods by S. Fujimoto et al., published in ICML 2018 [pre-print]
The first paper in this series looked at DDPG and highlighted a source of bias in the learning update. They introduced TD3, the latest and greatest algorithm in the DPG family, which essentially involves introducing a second critic network. Their fixes were very effective on MuJoco tasks compared to other SOTA approaches.
Addressing Sample Inefficiency and Reward Bias in Inverse Reinforcement Learning by Kostrikov et al., accepted at ICLR 2019 [pre-print]
Note: the title has been changed to “Discriminator-Actor-Critic: Addressing Sample Inefficiency and Reward Bias in Adversarial Imitation Learning” since I first read the paper, and a link to the most recent version from OpenReview is here. I recommend reading the discussion in the comment threads for a technical but illuminating conversation about the paper.
This paper is of the same vein as the one mentioned above. One of the ideas here is to use off-policy RL with GAIL (employing a replay buffer) to more efficiently solve inverse RL problems. The other big contribution is properly handling rewards for absorbing states; apparently, this is a big issue with applying inverse RL to certain MDPs, and can prevent the agent from ever matching the expert policy due to “reward bias”. They suggest a fix for explicitly learning rewards for absorbing states in GAIL, and show that it significantly improves performance.
Imitation learning really took off in 2018, so look for GAIL-type algorithms as well as TD3 to make a big impact in the near future.
I wrote a detailed paper summary on these two papers earlier this year, so check that out if you’re interested in learning a bit more.
(Sorry, I kind of cheated and put 2 papers under 1!)
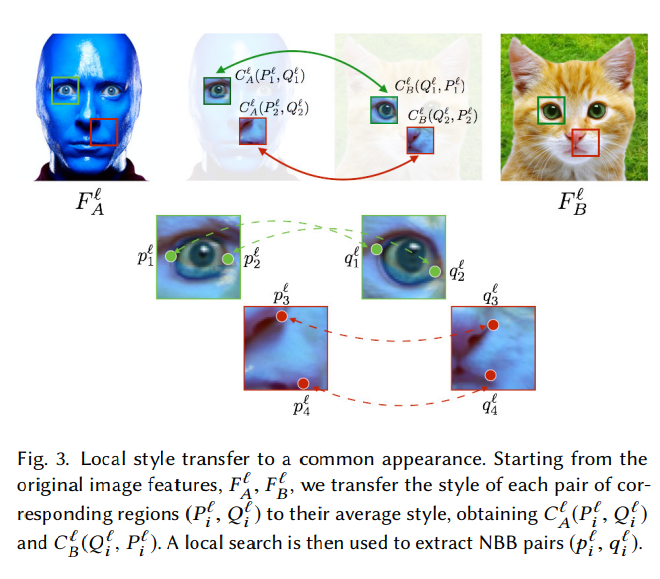
3. Neural Best Buddies: Sparse Cross-Domain Correspondence
By Aberman et al., published in SIGGRAPH 2018 [pre-print]
This paper looks at semantic correspondence across object categories—most semantic correspondence approaches are only trained/tested on image pairs of objects of the same category (e.g., aligning images of cow$\rightarrow$cow or dog$\rightarrow$dog). I think this is mainly because they rely on CNN features extracted from pre-trained object recognition deep nets like ResNet, Inception, or VGG, and the salient CNN features for an image of a cow aren’t really useful for finding corresponding salient features of a plane. However, with a nifty style transfer trick and a clustering+search algorithm for finding “neural best buddy” features, this paper shows that it’s possible to align images of vaguely related objects (e.g., cat$\rightarrow$lion).
Their approach is so clever and simple, and produces visually amazing results, which is why it made my list.
4. Discovery of Latent 3D Keypoints via End-to-end Geometric Reasoning
By Suwajanakorn et al., published in NeurIPS 2018 [proceedings]
Here’s a neat algorithm for unsupervised learning of 3D keypoints for particular object categories. The key idea is multi-view consistency; given two views of a 3D object, their deep network predicts the 3D keypoints that could have produced the relative pose difference. As supervision, the ground truth pose is needed, but not ground truth keypoints. Their model can localize keypoints even through occlusion and reason about difficult object symmetries. Check out their webpage for cool visual examples.
The multi-view consistency training objective is reminiscent of GQN, which also used a multi-view loss. This and a differentiable pose error loss made the paper stand out to me—I think the techniques used in this paper will be pretty useful for solving related problems.
5. LF-Net: Learning Local Features from Images
By Ono et al., published in NeurIPS 2018 [proceedings]
The problem of learning local descriptors for downstream tasks like pose estimation and scene reconstruction has been worked on extensively, so it was cool to see a powerful new deep learning approach come out. LF-Net surpasses LIFT and SuperPoint, two previous deep learning approaches that garnered lots of attention. One of the aspects of the paper that made me excited about it was the use of an optimization trick from RL—the one in DQN where the Q-targets for the Bellman loss are generated by a target Q-network whose weights slowly track the original Q-network’s weights. This highlights one of the biggest ways in which I’m seeing RL make an impact on the wider ML research community; it is introducing new optimization techniques for handling hard non-differentiable/non-convex/sparse-learning-signal type problems.