Deep Exploration via Bootstrapped DQN
Summary
This paper presents a novel approach to replace the classic epsilon-greedy exploration strategy. The main idea is to encourage deep exploration by creating a new Deep Q-Learning architecture that supports selecting actions from randomized Q-functions that are trained on bootstrapped data. This is a quick look at the proposed architecture.
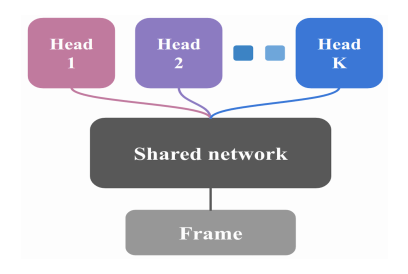
Bootstrapped DQN architecture
Each head represents a different Q-function that is trained on a subset of the data. The shared network learns a joint feature representation across all the data; it can be thought of as a data-dependent dropout. For DRL, samples stored in a replay buffer contain a flag marking which of the K Q-functions it came from.
The algorithm speeds up learning compared to other exploration tactics for DRL since it encourages deep exploration; at the beginning of each episode, a different Q-function is randomly sampled from a uniform distribution and it is used until the end of that episode.
Another key component of the Bootstrapped DQN algorithm is the bootstrap mask. The mask decides, for each Q-value function, whether or not it should train upon the experience generated at step t. Each individual experience is given a randomly sampled mask m ~ M, where M is Bernoulli, Poission, etc. Then, when training the network on a minibatch sampled from the replay buffer, the mask m decides whether or not a specific Q-value function is to be trained upon that experience. The authors show that the effect of this on the learning process is akin to dropout. This heuristic, plus the randomized Q-value functions, help Bootstrapped DQN deal with learning from noisy data and exploring complex state/action spaces efficiently.
Strengths
The authors based their idea on sound statistical principles and conducted numerous experiments to back up their claims. Their results show that Bootstrapped DQN can learn faster (but not necessarily with higher long-term rewards) than state-of-the-art DQN. The authors also compare their work with Stadie, Levine, and Abeel’s paper on Incentivizing Exploration in RL. See my previous post for details. The authors show that Bootstrapped DQN outperforms Stadie’s methods, as Stadie’s methods attempt the more ambitious task of learning a model of the task dynamics and using how well the agent has learned said model to inform the exploration.
Weaknesses
The paper is a bit hard to follow at times, and you have to go all the way to the appendix to get a good understanding of how the entire algorithm comes together and works. The step-by-step algorithm description could be more complete (there are steps of the training process left out, albeit they are not unique to Bootstrap DQN) and should not be hidden down in the appendix. This should probably be in Section 3. The MDP examples in Section 5 were not explained well; it feels like it doesn’t contribute too much to the overall impact of the paper.