A Symmetric and Object-centric World Model for Stochastic Environments
Patrick Emami, Pan He, Anand Rangarajan, Sanjay Ranka.
NeurIPS Object Representations for Learning and Reasoning Workshop. 2020. (Spotlight presentation)
tl;dr: We identify limitations of applying certain object-centric world models to stochastic environments and propose a state space model and training objective that achieves better stochastic future prediction.
Abstract
Object-centric world models learn useful representations for planning and control but have so far only been applied to synthetic and deterministic environments. We introduce a perceptual-grouping-based world model for the dual task of extracting object-centric representations and modeling stochastic dynamics in visually complex and noisy video environments. The world model is built upon a novel latent state space model that learns the variance for object discovery and dynamics separately. This design is motivated by the disparity in available information that exists between the discovery component, which takes a provided video frame and decomposes it into objects, and the dynamics component, which predicts representations for future video frames conditioned only on past frames. To learn the dynamics variance, we introduce a best-of-many-rollouts objective. We show that the world model successfully learns accurate and diverse rollouts in a real-world robotic manipulation environment with noisy actions while learning interpretable object-centric representations.
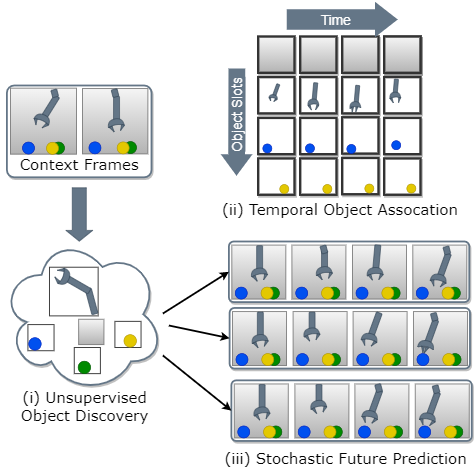
Demos - BAIR Towel Pick 30K with noisy actions
From left to right: ground truth, Ours, OP3, VRNN:












Object decompositions, Ours:




